Serverless computing refers to a model where the existence of servers is entirely abstracted away. Even though servers exist, developers are relieved from the need to care about their operation. They are relieved from the need to worry about low-level infrastructural and operational details such as scalability, high-availability, infrastructure-security, and other details. Serverless computing is essentially about reducing maintenance efforts to allow developers to quickly focus on developing code that adds value.
🎓 We will work through three labs in this session:
Lab1: Create, build, and run a cloud-native JavaScript serverless app in less than 15 minutes
Lab2: Create, build, and run a cloud-native JavaScript serverless application that uses the Visual Recognition service to determine image content
Lab3: Create, build, and run three serverless functions as a sequence
Lab4 (optional): Create, build and run an action that listens for changes in a database using actions, triggers and rules
Extensive evidence has shown that AI can embed human and societal bias and deploy them at scale. And many algorithms are now being reexamined due to illegal bias. So how do you remove bias & discrimination in the machine learning pipeline? In this talk you'll learn the debiasing techniques that can be implemented by using the open source toolkit AI Fairness 360.
AI Fairness 360 (AIF360) is an extensible, open source toolkit for measuring, understanding, and removing AI bias. AIF360 is the first solution that brings together the most widely used bias metrics, bias mitigation algorithms, and metric explainers from the top AI fairness researchers across industry & academia.
In this talk you'll learn:
- How to measure bias in your data sets & models
- How to apply the fairness algorithms to reduce bias
- An introductory look at how bias & discrimination can arise within modern machine learning techniques and the methods that can be implemented to tackle those challenges.
- Learn how to evaluate the metrics using the open-source AI Fairness 360 Toolkit to check for fairness and mitigate machine learning model bias.
Most of us use some sort of messaging/collaboration applications in our work places. Join us in this hands-on online meetup to create a chat moderator from scratch. We will be using the following services during the workshop:
- Natural Language Understanding: to detect different sentiments and emotions in text sent in Slack channels
- Visual Recognition: to detect offensive images sent in Slack channels
- Apache OpenWhisk: to glue together different pieces and create a complete application
Who is this workshop for? - Junior developers who want to see how to glue together different services and build an application from scratch
- Learn about hooking together different APIs using Serverless as the glue
- Developers interested in learning more about IBM services on the cloud
- Fun folks who want to do some pair programming!

This is an introduction to Machine Learning using IBM Watson Studio suite of products. We will introduce the tooling followed by a demo of Classification and Regression. Watson Machine Learning empowers your cross-functional team to deploy, monitor and optimize models quickly and easily. Once a model is deployed, APIs are generated automatically to help developers infuse AI into their applications quickly.
We will demo end to end machine learning lifecycle in this demo
-
Gather data and store on IBM Cloud Storage.
-
Data wrangling and cleanup using IBM Refinery.
-
Use Watson Machine Learning to create several classification and regression models.
-
Ask Watson Studio to pick the best performing model for you.
-
Deploy the model and then create a web application for prediction.
-
Learn how to continuously evaluate this model and improve over time.Introduction to Machine Learning on IBM Watson Studio
from sklearn.linear_model import LinearRegression
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error, r2_score
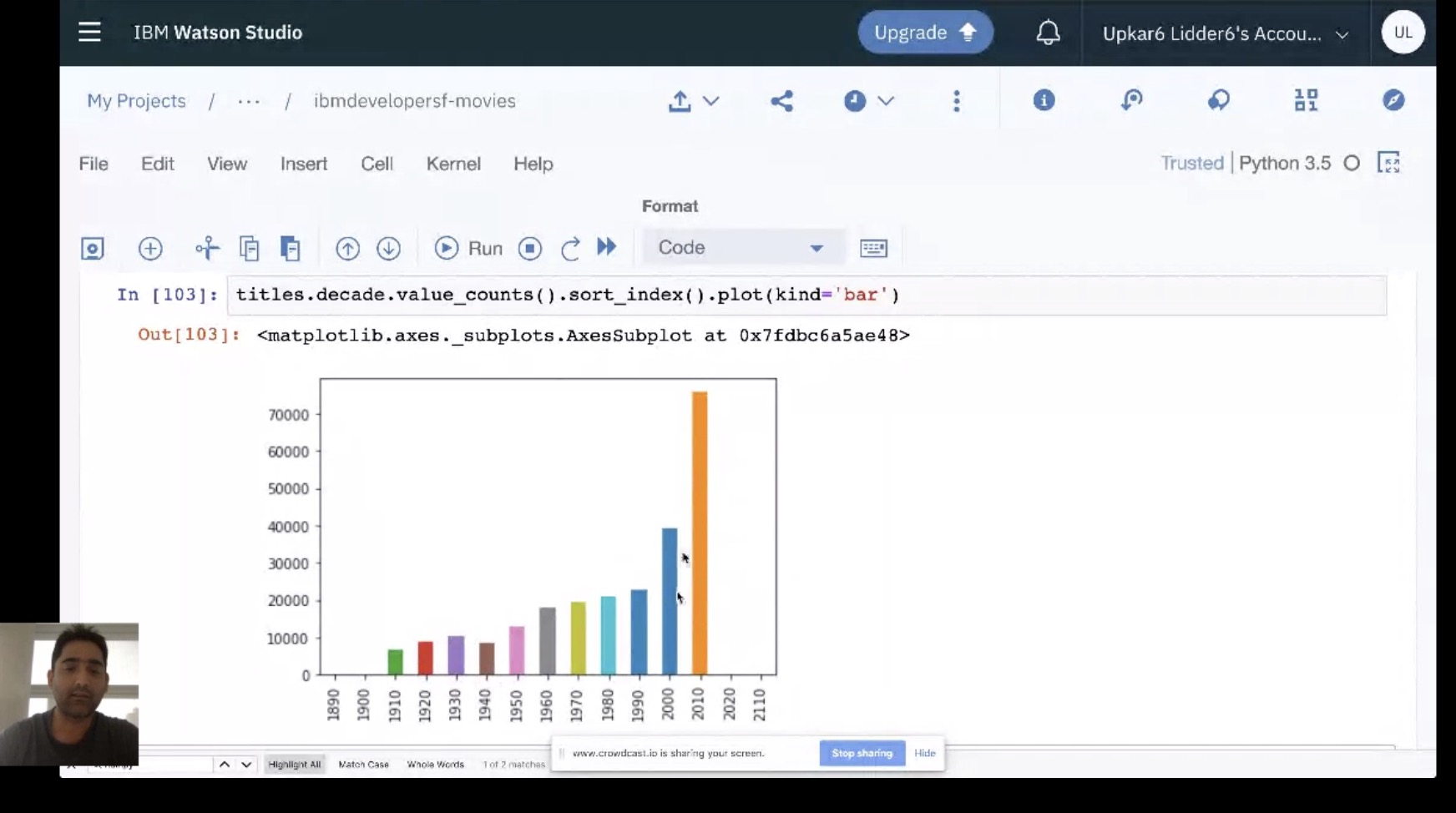
This is an introductory session on exploring and analyzing data using Python, Pandas and Jupyter Notebooks. We will go over:
- how to obtain/read a data file using python in Watson Studio
- how to clean noise in data
- selecting and querying data
- reshaping and filtering data
- grouping data into a hierarchy
- simple graphing of data
This is a good session for you if you are
- an aspiring data scientist
- frequently working with excel files and want another approach to dissect data
- a SQL developer looking to get into programming
- curious about data in general!
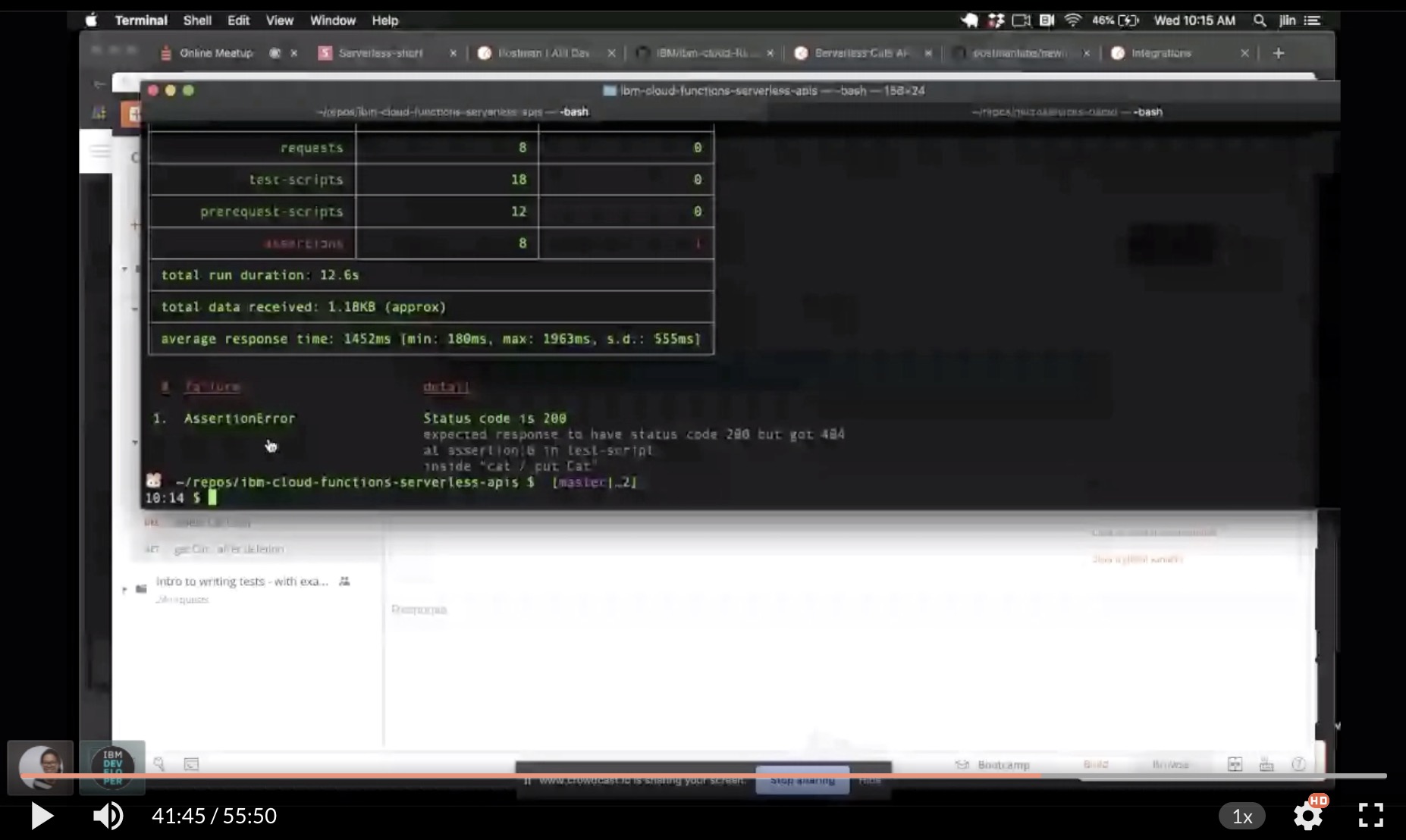
IBM and Postman are partnering up to show you how to use open source tools to create and test scalable and secure APIs!
Application programming interface, or APIs, are essential to any solution or software and need to be tested individually and in integration with other moving pieces. Testing APIs as an activity can be owned by the developers, the QA testers, or both. The QA team generally does not have access to the code. They write scripts and harnesses to test the APIs. We will show you how easy it is to use Postman to create test cases and scripts that can be run automatically on APIs created on serverless platforms!

Spark and PixieDust! What cool names! They also happen to be two of my favorite open source tools to explore and analyze data (also known as "data wrangling" in the cool circles!).
We are going to dive into both of these tools and explore a dataset. We will look at what makes data noisy and what to do with this "noise." You will also build some pretty cool visualizations using PixieDust! At the end of the workshop, you will have an idea on how to write an interesting and intriguing notebook or report, and how to build a portfolio over time.
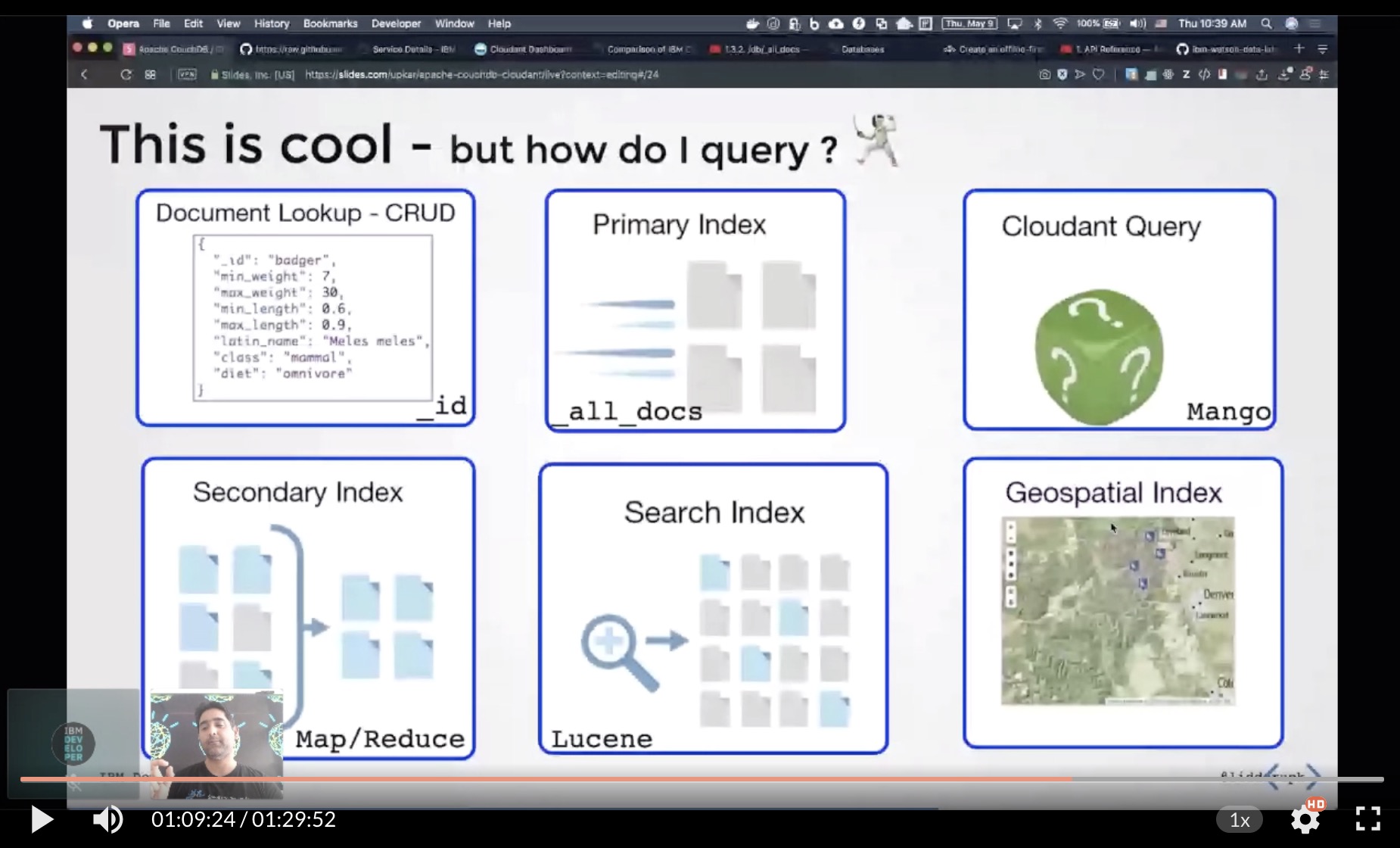
Join IBM Developer SF to get an introduction to Apache CouchDB - an open-source document-oriented database software that focuses on ease of use and having a scalable architecture.
A database in CouchDB is not a group of tables, but a collection of documents (JSON objects). We will use Cloudant, a hosted version on IBM Cloud, for the demo to avoid spending time installing locally.
We will look at how to create a simple CRUD application in CouchDB and then explore more advance features including:
1. Design Documents to transform, update and validate documents
2. Views to query documents using MapReduce
3. Mango Query Server to write JSON queries
4. HTTP API that makes CouchDB ideal for the web

Now that you have a bot live and deployed to your favorite social media, how can you continue to gather user feedback and improve your conversation ? How can the bot start to learn new terminology and content using your help ? We will look at the various metrics provided by Watson Assistant as well as adding code to our client and backend to improve our chatbot.
4-part online meetup series (meetup #4)

Now that you have a functioning bot, let’s deploy it to slack ! We will explore using the built in Watson Connector as well as the botkit middleware. Additionally, we will see how some of the features of Watson Assistant surface in slack and how you can use features unique to slack to enhance your conversation. We will also briefly go over other social media channels.
4-part online meetup series (meetup #3)

We built a basic chatbot in part I. We continue the journey by adding more digressions and handlers to our bot thereby giving it a personality. Additionally, we will explore the more advanced features in Watson Assistant using the JSON editor. Finally, we will add a backend service layer built on IBM functions and IBM cloud. This enables our chatbot to queries other systems and databases to better assist the user during a conversation. We will go into the two types of communications offered in Watson Assistant - server and client.
4-part online meetup series (meetup #2)

Learn the fundamental concepts behind creating a chatbot that can have meaningful and natural conversations. You will learn about the Watson Assistant service and the building blocks of a conversation including intents, entities, slots, digressions, handlers and dialogs. We will also use context variables to remember our users and not get too annoying!
4-part online meetup series (meetup #1)